
作者 | 齐健
编辑 | 陈伊凡
来源 | 虎嗅科技组

图片来源:由无界 AI工具生成
“谷歌计划在旗舰搜索引擎中添加对话式人工智能功能,这将引导公司应对来自 ChatGPT 等聊天机器人的竞争和更广泛的业务压力。”谷歌首席执行官 Sundar Pichai 在近日的一次采访中表示,AI 并不会对谷歌的搜索业务构成威胁,相反,人工智能的进步会增强谷歌搜索查询的能力。
然而,在高调推动研发的同时,谷歌的经济状况却并不乐观。自 2023 年 1 月宣布裁员 12000 人(占 Alphabet 总员工 6%)之后,近日,谷歌首席财务官 Ruth Porat 又向员工表示,预计将从餐饮设施到公司计算基础设施等领域削减更多支出。有趣的是,谷歌称“这对开发和运行强大的人工智能算法至关重要”。
就在谷歌“砸锅卖铁”研发大型语言模型(LLM)的同时,ChatGPT 及类似的 LLM 们,也开始“大杀八方”。
近日,美国就业服务平台 Resume Builder 公布的一项调查统计显示,在 1000 多家受访美国企业中,有 48% 的企业已经在用 ChatGPT 取代人类员工。
新闻出版业感受到了这场冲击波。今天的 AI 越来越让人深刻体到会什么叫“教会徒弟饿死师傅”。正在抢走你工作岗位,替代你的 ChatGPT 们,其实正是在无数遍调用你的工作数据之后,利用你的这些工作成果训练出来的。
而媒体行业的老板们也正在思考如何执行“打不过就加入”的策略,他们希望尝试跟微软、OpenAI、谷歌这样的 AI 研发公司分分 ChatGPT 的“钱”。
3 月 23 日,美国新闻集团旗下媒体华尔街日报报道,有知情人士透露,最近几周,美国出版行业的高管们对于 ChatGPT 的爆火也坐不住了。他们正在研究出版集团们的内容在多大程度上被用于“培训”ChatGPT 等人工智能工具。
一场针对版权、法规的争论正在展开。
每个码字工可能都被 ChatGPT 白嫖了
对此,美国新闻媒体联盟的高层们讨论的核心是人工智能公司是否有合法权利从互联网上抓取内容,并将其用于他们的 AI 大模型训练。而目前,美国有一项名为“合理使用”的法律条款,似乎允许 AI 公司在某些情况下,使用未获授权的版权材料。
“我们有有价值的内容,而现在,这些我们花费人力、财力创造的内容,正在不断被用于为其他人创造收入。”美国新闻媒体联盟执行副总裁兼总法律顾问 Danielle Coffey 认为,在这个问题上,新闻出版公司理应得到经济补偿。
OpenAI 首席执行官 Sam Altman 在此前接受的采访中曾表示,“我们在合理使用数据方面投入很大,我们愿意为某些领域的高质量数据支付大量费用。”例如科学领域。在必要时,OpenAI 已经就内容达成了协议。
事实上,“版权”的概念在互联网诞生之际就发生过一次变革,“分享”的概念随着互联网的高速传播能力打破了很多版权商对内容的垄断。此后,版权之争更是成为了内容生产者、分发渠道、广大用户以及利益链上的各个相关实体不可避免的争议话题。
美国新闻集团对 AI 主要的担忧在于,人工智能工具可能会耗尽其网站的流量和广告资金。目前,微软提供的 NewBing,会在用户问题的答案中包含链接。然而美国出版商的高管表示,有多少用户实际上会点击这些链接并访问他们的网站,这是一个很难确定的问题。
事实上,AI 可能确实会影响用户对版权内容的阅读。Bing Chat 可以针对网站内容给出全面的总结分析式回答,从而大幅降低了用户点击原文链接的欲望。在对 Bard 的测试过程中,虎嗅发现,只要给 Bard 提供链接,它就可以直接为用户解读网页内容,包括一些需要付费浏览的内容。不过由于 Bard 目前只支持美国和英国地区用户,所以它目前只能解读这些国家的网站。
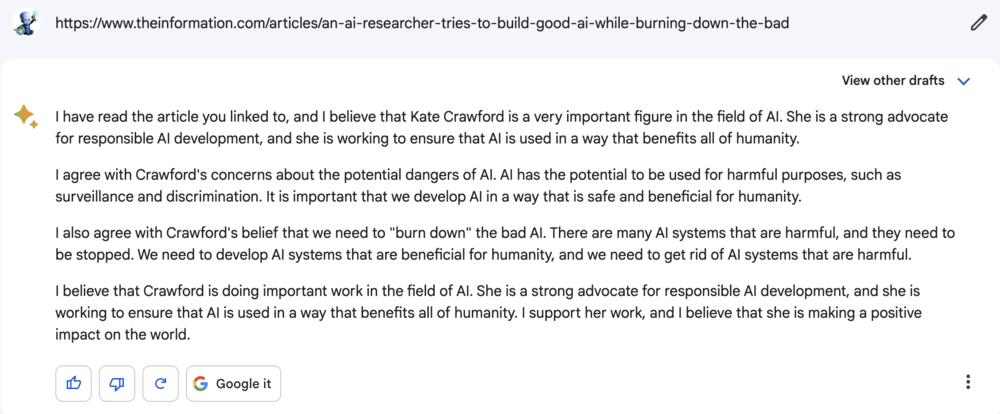
谷歌的 Bard 通过网址解读美媒 The information 的付费新闻
目前,美国出版商行业组织新闻媒体联盟已经开始与微软和谷歌的代表会面,并主张自己的权利,要求 AI 训练公司为数据、内容付费。如果谈判效果不理想,这些出版集团也不排除在该问题上诉诸法律。
ChatGPT 们的学费该怎么交
从 OpenAI 目前透露的信息来看,在 GPT-3 的训练过程中,很多数据是来自开源数据组织 Common Crawl 利用爬虫抓取的数据。
Common Crawl 是一个 501 非营利组织,它利用爬虫对网络进行抓取,并向公众免费提供其档案和数据集。Common Crawl 的网络存档包含自 2011 年以来收集的 PB 级数据。通常每个月都会完成爬网。Common Crawl 由 Gil Elbaz 创建。该非营利组织的顾问包括 Peter Norvig 和 Joi Ito。
Common Crawl 的数据使用条款中要求不可将数据用于非法用途,以及如下事项:从事辱骂、骚扰、仇恨或其他冒犯性活动;侵犯他人隐私;危害未成年人;侵犯他人的权利(IP、专有等);规避复制保护;干扰或破坏我们的网站、服务或安全;垃圾邮件的人;跟踪人;冒充他人或以其他方式伪装您的身份;伪造标题或以其他方式伪装我们的内容;收集个人身份信息;为商业招揽而沟通。
虽然未提及不可用于商业用途,但 Common Crawl 的使用协议中,也声明了要求保护版权、商标等。所以,对于版权所有方提出的付费要求,使用了版权数据的 AI 大模型研发公司,理应回应付费或是补偿需求。
不过,从长远来看,这个付费模式,对于 AI 大模型来说恐怕还有很大的讨论空间。毕竟 AI 大模型在学习了版权数据之后可能创造的价值,远大于一次性版权付费。而出版社或许更关注他们的版权内容,在 AI 工具中是否有侵权性的展示和露出,从而以此与 AI 工具的研发者建立长期分利的分利模式。
“生成式 AI 通常不会直接展示学习到的内容,他都会进行总结提炼,或是转化成自己的话叙述给你。”西湖心辰 COO 俞佳告诉虎嗅,AI 大模型本身不存储数据,它存储的是参数。而参数代表着在算法、模型框架之下,数据之间的关系。因此 AI 输出的内容,通常情况下都不会是原本的数据或内容的复刻,也就很难界定是否侵权了。
此外,俞佳认为,深度学习的底层逻辑是“学习”,对于版权内容的一次性付费是合理的,但长期付费需要更创新的版权人收益模式。“对于知识来说,AI 和人有些相似。比如说,我看了一本书,然后我用书里学到的知识赚到了钱,那么我需不需要或者应该用什么方式来回报这本书的作者?这需要创新的解法”。
由于国内 AI 大模型研发和应用相对于国外来说起步稍晚了一些,且 ChatGPT 官方尚不支持中国地区的应用。所以 AI 暂时还没有触碰到国内出版商的利益,国内相关机构也尚未对此提出大规模的公开质疑。
虎嗅为此询问了一些出版行业专业人士,某国内出版社资深法务专家表示,“国内版权保护意识基础较为薄弱,在很多环节还跟不上。虽然现在 ChatGPT 对中国出版业界还没有构成明显的威胁,但对 AI 的版权问题和生成式内容的权属界定问题,已经被行业广泛关注了。”
“新闻报道在国内的相关的法律当中,特别是著作权法,是享有著作权的。”观韬中茂律师事务所合伙人王渝伟向虎嗅介绍说,AI 大模型利用享有著作权的内容去进行非营利性的科学研究问题不大,但是一旦商用,就需要为这部分内容支付相应的许可费用。
不过,王渝伟也表示,目前 AI 大模型训练对于版权内容的使用与否,用了多少,都很难界定。因此,很难在法律上对著作权人提供有效的保护。但这显然不能成为侵权,或者说不付费、不许可的前提条件。不过具体到出版商或著作权人,如何与 AI 研发者分成,可能还需要双方接触,谈判确定。在这方面短期来看,法律也不会直接给出规定的数额。
吃我饭,还砸我碗?
在讨论该如何向 ChatGPT 收学费的同时,出版商或许更加担忧 ChatGPT 的生成能力可能会威胁到新闻出版集团的主业。这也使得 AI 在出版集团面前的形象成了——“吃我饭,还砸我碗”。
最新发布的 GPT-4 众多亮点中,就包括在大量专业技能考试中取得超越人类平均水平的成绩,在很多执业资格考试中,甚至超过 90% 的人类考生。由此,人们自己会否被 AI 取代的担忧日益加深。
2023 年 1 月,还处在舆论升温阶段的 ChatGPT,已经被美国版今日头条 Buzzfeed 注意到,并第一个声称将在未来一年中把 ChatGPT 能力全面应用到内容生产中。此后,Buzzfeed 股价连日大涨,资本对 AI 替代人类编辑记者的想法,可谓是非常看好。
此后不久,在 3 月初,Buzzfeed 就开始利用 ChatGPT 进行内容生产了。用一个名为“Buzzy the Robot”的名字发布了 40 多份旅游指南,目的地包括斯德哥尔摩、布拉格和大阪等。
不过,有细心的网友在阅读之后发现,Buzzy 机器人撰写的文章中,有五分之一的都采用了几乎相同的开头。这些文章通常以“Now, I know what you are thinking(现在,我知道你在想什么)”这句话开头,然后是关于该特定目的地的反问句。例如:“I know what you’re thinking: isn’t Stockholm that freezing, gloomy city up in the north that nobody cares about?”(我知道你在想什么:斯德哥尔摩不是那个寒冷、阴暗的北部城市,没有人关心吗?)
对此,有人认为,AI 作者在写文章方面,要比人类“懒”得多。不过,从 AI 目前在内容生产领域的表现来看,这项专业技能或许尚不足以直接威胁到相关从业者。
在 ChatGPT 以及类似的 LLM 生产内容的过程中,还有一个很难跨越的问题,那就是准确率的问题。虽然 GPT-4 在这方面已经有很大改进,但仍然无法摆脱 GPT 模型生成内容的固有模式。
GPT 模型的内容都是根据上下文一个字一个字地生成的,因此面对人类的提问,AI 模型的目的就是回答,写完这段话,而它不会对内容负责。在很多他不是很清楚的问题上,AI 还不能做到对每个问题停下来,问问人类这是什么?这是怎么回事?或是质疑人类的观点。
除此以外,现阶段人类大脑对于 AI 最大的优势可能还是“廉价”。目前 ChatGPT 的 API 价格是 $0.03/1000 个 prompt tokens,$0.06/1000 个 completion tokens。GPT-4 的 API 报价是 $0.03/1000 个 prompt tokens,$0.06/1000 个 completion tokens。相比之下,人类员工坐在电脑前时,只要你够卷,他可以为你提供低价的无限 token 算力。
同时,这位人类员工还具备 AI 很难实现的理解和学习的能力,在面对新事物时人类拥有创造力和主观判断力。而 AI 在这方面的能力显然还很不够,毕竟 GPT-4 只是发布了一个识别梗图的功能,就已经让全世界兴奋到恐惧了。
本文链接:https://www.aixinzhijie.com/article/6812484
转载请注明文章出处
