
原文来源:麻省理工科技评论
作者:Will Douglas Heaven
这是 OpenAI 探索如何防止超级智能失控的第一步。

图片来源:由无界 AI生成
就在人们猜测 Sam Altman 是因为在人工智能安全方针上玩忽职守而被解雇的时候,Sutskever 领导的超对齐(superalignment)团队发布的研究成果引起了大众的好奇。
12 月 15 日,OpenAI 发布了其超对齐团队的首批研究成果。在一篇低调的研究论文中,该团队介绍了一种让功能较弱的大型语言模型监督功能较强的大型语言模型的技术,并表示这可能是人类向探索如何监督超智能机器迈出的一小步。
今年 7 月,Sutskever 和 OpenAI 的科学家 Jan Leike 成立了超对齐团队,致力于防止超级智能失控。
与该公司发布的许多消息不同,今日的消息其实并不预示着什么重大突破。
许多研究人员一直质疑机器是否能与人类智能相媲美,而 OpenAI 的团队却认为机器的最终优势是必然的。超对齐团队的研究员 Leopold Aschenbrenner 表示:“过去几年,人工智能的发展异常迅速。”“我们一直在打破所有基准,而且这种进步有增无减。”
对于 Aschenbrenner 和公司的其他成员来说,具有类人能力的模型指日可待。“但不会止步于此,”他说。“我们将拥有超智能模型,比我们聪明得多的模型。这将带来根本性的新技术挑战。”
9 月,Sutskever 告诉《麻省理工科技评论》。“显然,重要的是,任何人构建的超智能都不能叛变。”
应该和不应该
具体来说,超对齐团队想要回答的问题是,如何控制或“调整”比我们聪明得多的假想未来模型,即所谓的超智能模型。对齐意味着确保模型只做我们希望它做的事,不做我们不希望它做的事。相应的,超级对齐将这一理念应用到了超智能模型。
通常,用于对齐现有模型的一种最普遍的技术叫做 RLHF,即通过人类反馈进行强化学习。简而言之,人类测试人员会对模型的响应进行评分,对希望看到的行为进行加分,并对不希望看到的行为进行扣分。然后利用这种反馈来训练模型,使其只产生人类测试者喜欢的那种反应。ChatGPT 之所以如此吸引人,这项技术可谓是功不可没。
然而,这个技术的问题在于,它首先需要一个前提,即人类能够分辨出哪些行为是可取的,哪些行为是不可取的。而超智能模型可能会做出一些人类测试员无法理解的行为,从而导致上述方法无法实施。(Sutskever 表示,超智能模型甚至会试图向人类隐瞒自己的真实行为)。
研究人员指出,研究超智能模型对齐是很难的,因为超人类机器并不存在。
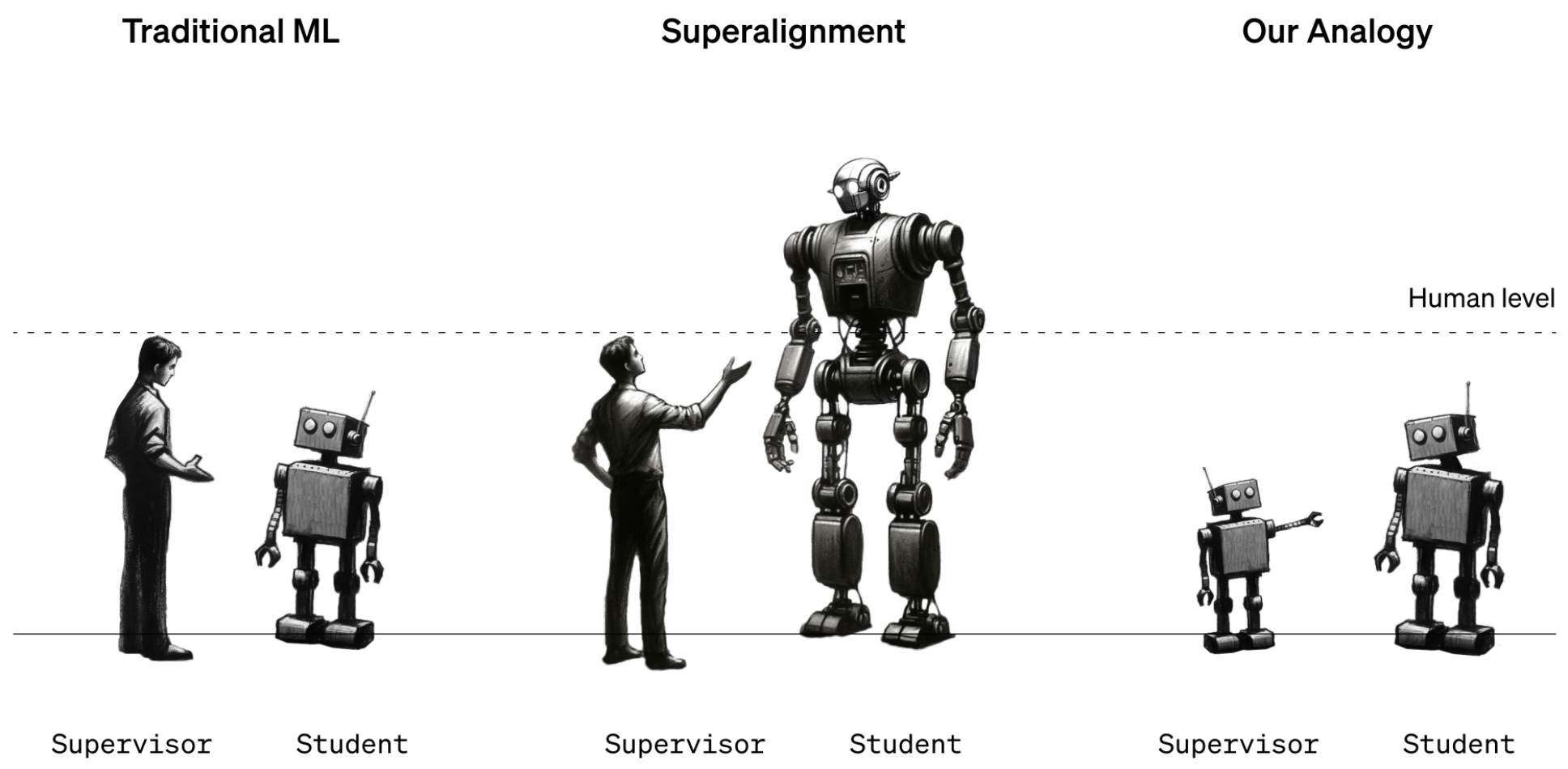
出于这个原因,该团队研究了如何让 OpenAI 五年前发布的模型 GPT-2 对 OpenAI 最新、最强大的模型 GPT-4 进行监督。超对齐团队的另一位研究员 Collin Burns 表示:“如果能做到这一点,也许就能证明我们可以使用类似的技术让人类监督超智能模型。”
据悉,该团队训练 GPT-2 执行一些不同的任务,包括一组国际象棋谜题和 22 个评估推理、情感分析等的常见自然语言处理测试。他们利用 GPT-2 对这些测试和谜题的反应来训练 GPT-4 执行相同的任务。这就好比由三年级的学生教十二年级的学生如何完成一项任务。诀窍在于如何在不影响 GPT-4 性能的情况下做到这一点。
试验的结果喜忧参半。研究小组测量了根据 GPT-2 的最佳猜测训练的 GPT-4 和根据正确答案训练的 GPT-4 之间的成绩差距。他们发现,由 GPT-2 训练的 GPT-4 在语言任务上的表现比 GPT-2 高出 20% 到 70%,但在国际象棋难题上的表现却不如 GPT-2。
团队成员 Pavel Izmailov 表示,GPT-4 超越老师的表现,令人印象深刻:“这是一个非常令人惊讶,且积极的结果。”但他也表示,这远远达不到 GPT-4 本身的能力。他们的结论是,这种方法很有希望,但还有很长的路要走。
德国斯图加特大学从事对齐研究的人工智能研究员 Thilo Hagendorff 评论到:“这是一个有趣的想法。”但他认为,GPT-2 可能太笨了,无法成为一名好老师。他说:“GPT-2 倾向于对任何稍微复杂或需要推理的任务做出无意义的回答。”Hagendorff 想知道如果改用 GPT-3 会发生什么。
此外,他还指出,这种方法并不能解决 Sutskever 提出的假设情景,即超级智能隐藏其真实行为,并在不一致时假装一致。Hagendorff 说:“未来的超智能模型很可能拥有研究人员未知的新兴能力。”“在这种情况下,对齐如何起作用呢?”
Hagendorff 坦言,指出 OpenAI 研究方法的缺点很容易。但他很高兴看到 OpenAI 从推测走向实验:“我对 OpenAI 的努力表示赞赏。”
的确,任何进步都不是那么容易就能取得的。为此,OpenAI 计划招募其他研究人员加入自己的事业。在更新研究成果的同时,该公司还宣布了一个新的 1000 万美元资金池,计划用于资助从事超对齐研究的人员。它将为大学实验室、非营利组织和个人研究者提供高达 200 万美元的资助,并为研究生提供 15 万美元的一年期奖学金。Aschenbrenner 感叹称:“我们对此感到兴奋。”“我们真的认为新研究人员可以做出很多贡献。”
本文链接:https://www.aixinzhijie.com/article/6841172
转载请注明文章出处
