
谷歌推出 BIG-Bench Mistake 数据集,可帮助大语言模型提升自我纠错能力。

随着人工智能技术快速发展,作为基础技术之一的大语言模型(LLMs)在推理任务中也越来越受欢迎,例如多回合问答(QA)、任务完成、代码生成或数学领域。
但是,LLMs 在第一次尝试时未必能够正确解决问题,尤其是在它们没有接受过训练的任务中。对此,谷歌研究人员指出,想要将此类模型能够发挥出最大作用,它们必须能够做到两点:1.确定其推理出错的地方;2.回溯(Backtrack)找到另一个解决方案。
这导致了行业内与 LLMs 自我纠正(Self-Correction)相关的方法激增,即利用 LLMs 来识别自身输出中的问题,然后根据反馈产生改进的结果。
谷歌研究人员表示,自我纠正通常被认为是一个单一的过程,但谷歌将其分解为两个部分:错误发现和输出纠正。
在《LLMs 无法发现推理错误,但可以纠正错误!》论文中,谷歌分别测试了最先进的大语言模型的错误发现和输出纠正能力。在此基础上,谷歌研究院最近使用自家 BIG-Bench 基准测试,创建了一项名为“BIG-Bench Mistake”的专用基准数据集,以进行一系列评估研究。具体如下:
1.LLMs 能否发现思维链(CoT)式推理中的逻辑错误?
2.在找到错误所在后,是否可以提示 LLMs 回溯并得出正确答案?
3.作为一种技能,错误发现是否可以推广到 LLMs 从未见过的任务中?
BIG-Bench Mistake 数据集
错误发现(Mistake Finding)是自然语言处理中一个尚未充分研究的问题,特别是在这个领域缺乏评估任务。为了更好地评估 LLMs 查找错误的能力,首先评估任务应该要展示明确的错误。正因如此,当前大多数查找错误的数据集都没有脱离数学领域。
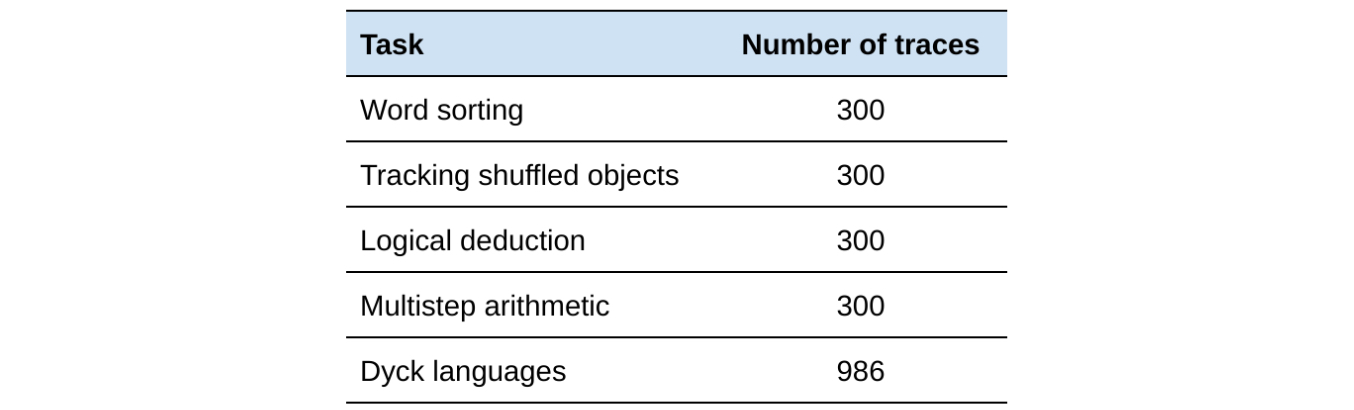
而谷歌生成的 BIG-Bench Mistake 数据集,则是为了评估 LLMs 对数学领域之外的错误进行推理的能力。研究人员通过 PaLM 2 语言模型在 BIG-Bench 基准测试任务中运行了 5 项任务,然后将这些任务中生成的“思维链(Chain-of-Thought)”轨迹组合成这项数据集。据称,每个轨迹都标注了第一个逻辑错误的位置。
为了最大限度地增加数据集中的错误数量,提升准确程度,谷歌研究人员反复操作提取了 255 条答案错误的轨迹(可以确定肯定存在逻辑错误)和 45 条答案正确的轨迹(可能存在错误,也可能没有错误)。谷歌还要求人工标注者查看每条轨迹,并找出第一个错误步骤,并确保每条轨迹都至少由三位标注者进行标注,使得最终的答案具有 >0.98 的评级间可靠性水平(使用 Krippendorff 的 α)。
研究表明,该数据集中出现的逻辑错误“简单且明确”,因此为“LLMs 发现错误的能力”提供了一个良好的测试标准,可协助 LLMs 先从简单的逻辑错误开始训练,然后再将其用于更难、更模糊的任务。
错误识别的核心问题
1.LLMs 能否发现思维链式推理中的逻辑错误?
首先,需要确定 LLMs 是否能独立于其纠正错误的能力来识别错误。谷歌尝试了多种提示方法来测试 GPT 系列模型错误查找的能力(此处假设它们能够广泛代表现代 LLMs 的表现)。
在实验过程中,研究人员尝试了三种不同的提示方法:Direct(trace)、Direct(step)和 CoT(step)。在 Direct(trace)中,谷歌向 LLM 提供 trace 并询问错误或没有错误的位置步骤。在 Direct(step)中,谷歌会提示 LLM 针对其采取的每一步询问自己这个问题。在 Direct(trace)中,谷歌则提示 LLM 给出每个步骤是否错误的推理。

研究人员发现,目前最先进的 LLms 自我纠错能力相对有限,即使是最好的模型总体准确率也仅为 52.9%。而研究发现与上文提到的论文结果一致,绝大多数 LLMs 可以识别在推理过程中出现的逻辑错误,但情况并不理想,仍然需要人工干预来纠正模型输出的内容。谷歌假设这是 LLMs 无法自我纠正推理错误的一个重要原因。
2.LLMs 能否在知道错误所在的情况下进行回溯?
在证明了 LLMs 在发现 CoT 轨迹中的推理错误方面表现不佳的情况下,谷歌下一项研究在于评测 LLMs 是否能纠正错误。
需要注意的是,知道错误位置与知道正确答案并不相同: 即使最终答案是正确的,CoT 轨迹也可能包含逻辑错误,反之亦然。谷歌研究人员提出回溯方法如下:
- 在温度值(temperature)= 0 时,照常生成 CoT 轨迹。(温度值是控制生成响应随机性的参数,较高的温度值会产生更加多样化和创造性的输出,通常以牺牲质量为代价。)
- 识别第一个逻辑错误的位置(例如使用分类器,或者此处只使用 BIG-Bench Mistake 数据集中的标签)。
- 在温度值 = 1 时重新生成错误步骤,并产生一组 8 个输出。由于已知原始输出会导致错误结果,因此目标是在此步骤中找到与原始输出显着不同的替代生成。
- 从这 8 个输出中,选择一个与原始错误步骤不同的输出。(目前只使用精确匹配,但将来可以使用更复杂的方法)
- 使用新步骤,在温度值 = 0 时正常生成轨迹的其余部分。
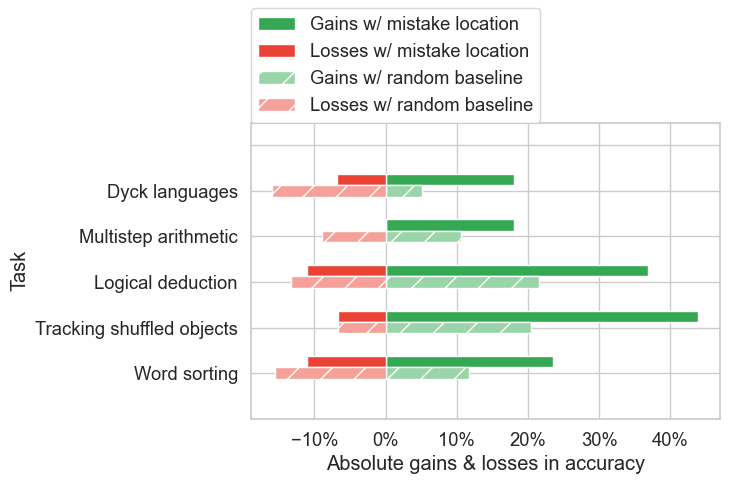
这是一种非常简单的方法,不需要任何额外的提示制作,并且避免了重新生成整个轨迹。在使用 BIG-Bench Mistake 的错误位置数据对其进行测试后,研究人员发现它可以纠正 CoT 错误。
值得一提的是,最近的研究表明,自我纠正方法(例如 Reflexion 和 RCI)会导致准确性分数下降,因为正确答案变为错误答案的情况,多于错误答案变为正确答案的情况。而谷歌的方法产生的“收益”(通过纠正错误答案)则多于“损失”(通过将正确答案更改为错误答案)。
除此以外,谷歌还将其方法与随机基线进行了比较。在随机基线中,谷歌随机假设一个步骤是错误的。结果表明,这种随机基线确实产生了一些“收益”,但不如在正确的错误位置回溯时产生的“收益”多,并且“损失”更大。
3.错误发现是否可以推广到 LLMs 从未见过的任务中?
为了回答这一问题,谷歌研究人员在 4 个 BIG-Bench 任务上微调了一个小模型,并在第 5 个未完成的任务上对其进行了测试。通过重复上述操作,谷歌总共生成了 5 个微调模型。然后,研究人员将结果与零样本提示 PaLM 2-L-Unicorn(一个更大的模型)进行比较。
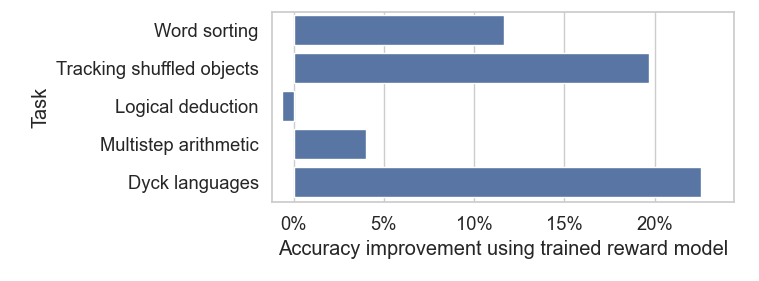
研究结果表明,经过相关测试任务微调后的小型奖励模型(reward model),通常比零样本提示大模型的表现更好,即使小型模型从未见过测试集中任务相关的数据。唯一的例外是在逻辑推理方面,它的表现与零样本提示大模型相当。
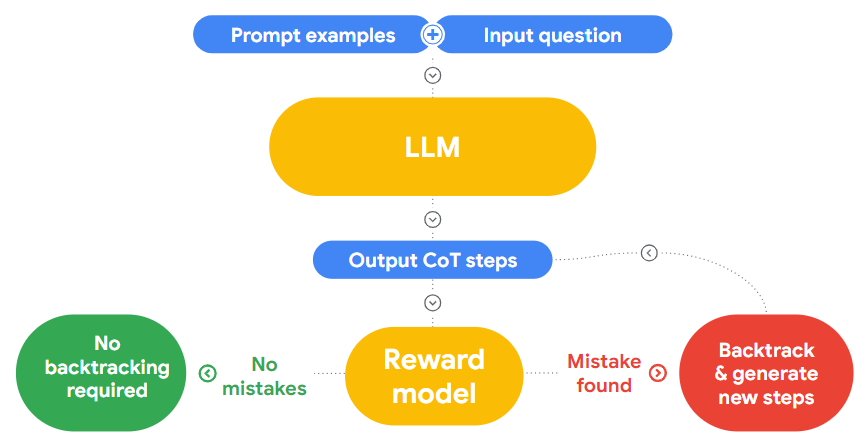
谷歌研究人员表示,这是一个非常有前景的结果。虽然相比小型模型的高效,大语言模型目前发现逻辑错误难度更高。但他们可以使用一个经过微调的小型模型来执行回溯,帮助大模型,并提高任何任务的准确性。并且小型模型完全独立于生成器 LLM,也可以针对单个用例进行更新和进一步微调。
文章来源:https://blog.research.google/2024/01/can-large-language-models-identify-and.html。
本文链接:https://www.aixinzhijie.com/article/6844008
转载请注明文章出处
